I was eight years old when my father graduated from college. He’d spent the better part of a decade working all day, going to school at night, and trying to manage three young boys somewhere in-between. I don’t remember when he found the time to do homework but I do remember that he had these really interesting magical-seeming books on his shelf or on his desk or on the kitchen table. Most of them were big and heavy with glossy pages and lots of pictures. Somewhere around the time I was nine or ten, my father handed me the smallest of these books, a thin, yellowed volume about the size and shape of a paperback and told me I should try reading this one. It was filled with many weird symbols and lots of black-and-white sketches of shapes and curves. It was called something like “Algebra and Trigonometry,” neither of which were words that I knew. He also gave me one of these:

And showed me how to use it to measure these things called “angles.” I remember leafing through this book and coming upon this really neat “fact,” namely that the sum of the measure of the angles in any triangle is 180 degrees. Now, this was interesting! I knew what a triangle was, I knew how to measure angles, and I knew how to add. This was something I could explore! So, dutifully, I began sketching triangles in my notebook, measuring the angles, and adding up the results. And, I quickly discovered something quite odd – my measurements didn’t always add up to 180. Sometimes I’d get 179.5 or 178 and sometimes 181 or 182. What, I wondered, was going on here? Was this magical book wrong? Had I discovered something new?
I remember showing my results to my father and him telling me it was my measurements that were wrong and imprecise. I wondered how he knew this and he explained that we don’t know that the sum is always 180 because we keep measuring triangles and discover this fact, but rather, we know this “fact” because of this thing called “proof.” It would be many, many years before I’d really start to understand this distinction but it’s this distinction I want to talk about here today and ultimately relate it to questions that seem to be swirling around concerning mathematical modeling and the notion of “real-world.”
Let’s continue to think about triangles. Here’s a triangle:

Now, the problem is that I’ve just lied to you. The thing that you’re looking at isn’t actually a triangle at all. Rather, the thing you’re looking at is a representation of the abstract mathematical concept of “triangle.” This is a fine distinction, but an important one. Triangles don’t actually “exist” in the same sense that my cat exists, or the sun exists, or a bottle of water exists. A triangle only exists as this abstract object that is brought to life by a mathematical definition. One example of such a definition is:
A triangle is a polygon that has precisely three sides.
Like all good definitions, this tells us the class of objects that our new object (triangle) belongs too, namely the class of things called “polygons,” and it tells us the specific difference between our new object and other elements of the class, “has precisely three sides.” The picture above is not a triangle, but rather is a picture of what one of these abstract things we call “triangle” might look like if we attempted to visualize it. But, and this is important, triangles themselves simply do not exist anywhere in this place we live, this place we call “the universe.” We can’t point to a triangle, we can’t draw one, we can’t pick one up, touch one, or taste one. They only exist in this abstract world that we call “mathematics.”
But, you ask, are triangles real? And, this is where the confusion begins. This is not an easy question. Plato believed that they were real and that somewhere there existed, in the same sense as my cat exists, this “abstract world of forms” populated by things like triangles and continuous functions and notions of “catness.” Plato believed that this abstract world of forms was the primary reality and that the world of substance and matter which we inhabit was but a mere shadow of this abstract world.
Of course, Aristotle disagreed and argued that no such world of forms existed and that our world of substance was the primary reality, that is, it was the world that my cat inhabits that is actually “real.” Plato and Aristotle’s disagreement sits in the center of the famous picture, “School of Athens” by Sanzio, which hangs today in the Vatican. Plato, on the left, points upward toward his “world of forms,” while Aristotle, on the right, points forward to what’s in front of us.

Now, what does all this have to do with mathematical modeling? Let’s go back to a definition of mathematical modeling put forth in the GAIMME report:
Mathematical modeling is a process that uses mathematics to represent, analyze, make predictions, or otherwise provide insight into real-world phenomena.
There is much debate and angst that arises around the very last part of that definition, namely the use of the term “real-world.” Some argue that triangles are “real” to children in a way that irrigation systems are not and hence conclude that doing any form of mathematics is doing mathematical modeling. This is, of course, where one falls into the trap of equivocation. In arguing in this way, one changes the meaning of “real-world” from indicating Aristotle’s world of substance and things to meaning “familiar to me whether it’s part of the world of substance or not.” This equivocation is the challenge and the fault. We need to use “real-world” in the sense that it’s intended by those who state definitions such as are found in the GAIMME report. We can’t arbitrarily change that meaning any more than we can change the meaning of “polygon” in our definition of triangle to include objects with curved sides and still expect our definition of “triangle” to make sense.
But, does this really matter? What’s lost if we change the meaning of “real-world” to be a subjective one that means “anything with which I’m familiar”? This is the truly important part. In making that shift, all is lost. All that is special, and powerful, and unique about this practice called “mathematical modeling” is dependent upon this connection to the “real world,” where here, the “real world” means the physical world, the natural world, Aristotle’s world of substance, or what we commonly refer to as the “universe.” The magic of mathematical modeling is that it connects Plato’s abstract world of forms (whether you believe in it or not) to Aristotle’s world of substance.
Mathematical modeling allows us to use the things we discover in the abstract world of mathematics to understand things in this other place, this space we inhabit, this non-abstract world of cats, and water bottles, and irrigation systems. The heart of mathematical modeling is the ability to bridge that gap, to make those connections, and to learn how to connect and use the abstract world to understand the world we inhabit. It’s the skills that are needed to work in that gap that is the new thing about teaching and learning mathematical modeling and that’s what we lose if we equivocate and redefine “real-world.”
The fact is that it is working in that gap that requires a new set of skills. And it’s this fact that makes the teaching and learning of mathematical modeling new and challenging. One must have an understanding of and be able to operate in the “mathematical world.” But, one must also have an understanding of and be able to operate in the “real world.” One must know or learn things about physics, or chemistry, or sociology, or farming, to be able to connect what they know in the mathematical world to this real world. One must learn how to make these connections, how to attach which abstract notions of mathematics to which phenomenon in this space we inhabit. One must learn the strengths and limitations of such connections and how to test them. Engaging in this practice or process and doing so in order to understand or make predictions about the “real world” is what we call “mathematical modeling.”


 ?
? , should be proportional to the bubble population:
, should be proportional to the bubble population:

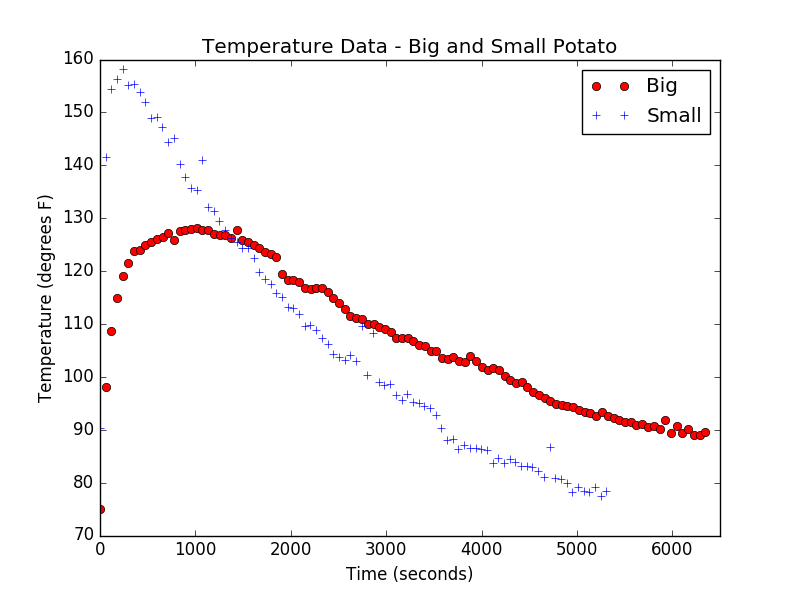
 is the number of bubbles at time zero. So, we expected our bubble population to simply exhibit exponential decay. Then, Alex (Alexandria) went to lab and started measuring. Rather than the nice exponential decay we expected, Alex found this:
is the number of bubbles at time zero. So, we expected our bubble population to simply exhibit exponential decay. Then, Alex (Alexandria) went to lab and started measuring. Rather than the nice exponential decay we expected, Alex found this: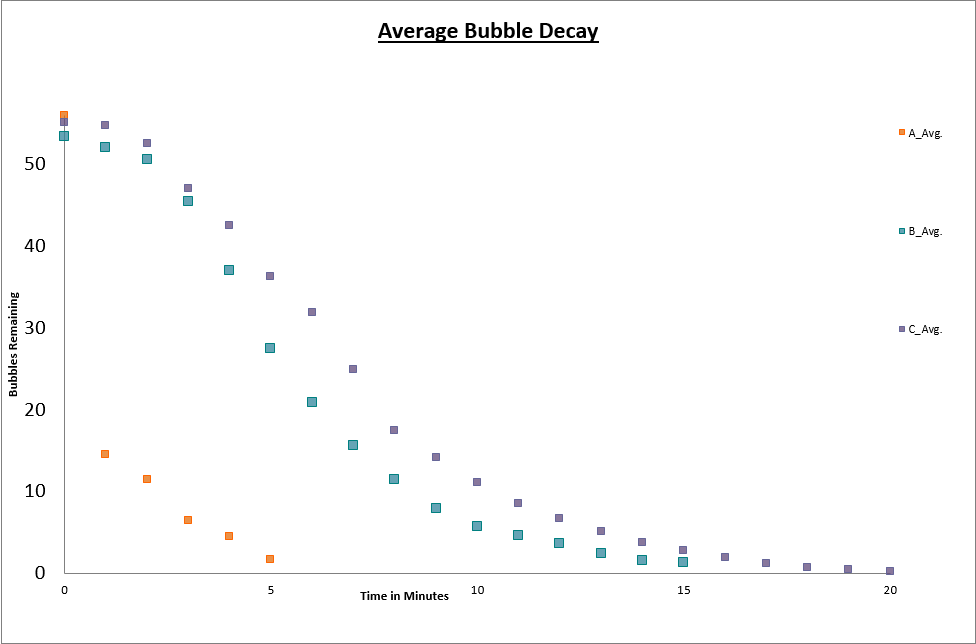



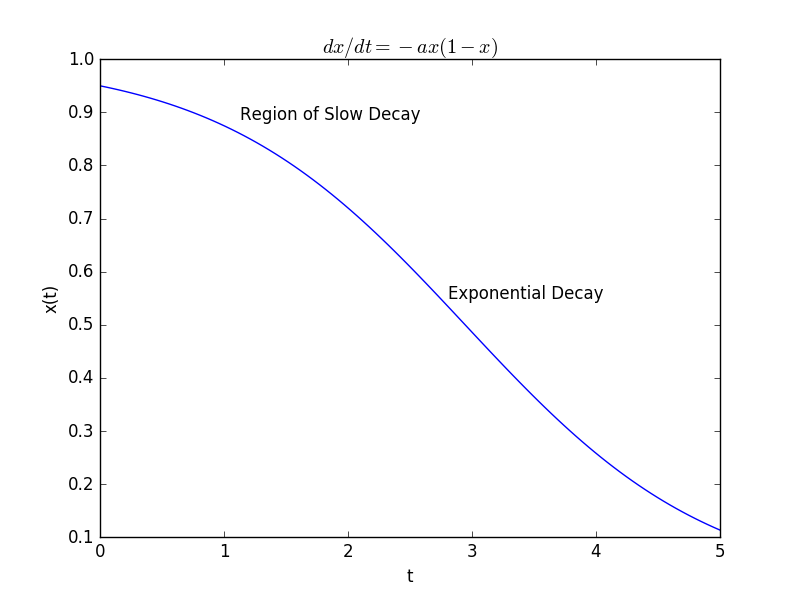
 in our new model relate to properties of our soap bubbles? How does the constant
in our new model relate to properties of our soap bubbles? How does the constant  relate to these properties? Is there some reason to believe our variable rate is the right one?
relate to these properties? Is there some reason to believe our variable rate is the right one?
 . Room temperature is
. Room temperature is  and initially the potato is at some higher temperature,
and initially the potato is at some higher temperature,  . There are four parameters in the model. The mass of the potato,
. There are four parameters in the model. The mass of the potato,  , the specific heat,
, the specific heat,  , which measures the amount of energy needed to raise a unit mass of potato one degree in temperature, the surface area of the potato,
, which measures the amount of energy needed to raise a unit mass of potato one degree in temperature, the surface area of the potato,  , and the heat transfer coefficient,
, and the heat transfer coefficient,  , which measures how fast the potato loses heat energy to the surrounding environment. We note that this model can be thought of as a statement of the principle of conservation of energy. The equation simply says the change in the energy of the potato is equal to the energy lost to the surrounding environment. The left-hand term is this change in energy, and the right-hand term relies upon Newton’s Law of Cooling which says that the energy lost to the surrounding environment is proportional to the difference between the temperature of the body and the temperature of the surrounding environment.
, which measures how fast the potato loses heat energy to the surrounding environment. We note that this model can be thought of as a statement of the principle of conservation of energy. The equation simply says the change in the energy of the potato is equal to the energy lost to the surrounding environment. The left-hand term is this change in energy, and the right-hand term relies upon Newton’s Law of Cooling which says that the energy lost to the surrounding environment is proportional to the difference between the temperature of the body and the temperature of the surrounding environment.

 . For each potato, since they differ in mass and surface area, we’ll have a different
. For each potato, since they differ in mass and surface area, we’ll have a different  and for our large potato,
and for our large potato,  .If we examine the ratio
.If we examine the ratio  , this ratio will give us our answer. If it’s bigger than one, the small potato must cool faster, if it is less than one, the large potato must cool faster. But, also notice that if we assume our potatoes are made of the same “potato-stuff” then
, this ratio will give us our answer. If it’s bigger than one, the small potato must cool faster, if it is less than one, the large potato must cool faster. But, also notice that if we assume our potatoes are made of the same “potato-stuff” then 




 ) and a TMP36 temperature sensor (
) and a TMP36 temperature sensor ( ). We wrote Python code to carry out the sensing, gather data every minute, and store the data to a file for later analysis. This let us get lots of data for each potato, carry out the experiment over a long-time (one and a half hours), and not need to be there to monitor the experiment. If you’re interested, I’ve pasted the Python code at the bottom of this post for you to use or copy as you see fit. Now, if you don’t want to go the route of microcontrollers and sensors, all you need to carry this experiment out is a way to measure temperature and a watch. You could use a Vernier temperature probe or even a good old-fashioned glass thermometer. To heat our potatoes we placed each one in the microwave oven for five minutes. We then stuck our probe into the middle of the potato as best we could, sat back, and let our potatoes cool. Here’s our simple setup:
). We wrote Python code to carry out the sensing, gather data every minute, and store the data to a file for later analysis. This let us get lots of data for each potato, carry out the experiment over a long-time (one and a half hours), and not need to be there to monitor the experiment. If you’re interested, I’ve pasted the Python code at the bottom of this post for you to use or copy as you see fit. Now, if you don’t want to go the route of microcontrollers and sensors, all you need to carry this experiment out is a way to measure temperature and a watch. You could use a Vernier temperature probe or even a good old-fashioned glass thermometer. To heat our potatoes we placed each one in the microwave oven for five minutes. We then stuck our probe into the middle of the potato as best we could, sat back, and let our potatoes cool. Here’s our simple setup:
 ?
?







 , could be written as:
, could be written as:

 are positive constants of proportionality. A little rearrangement yields:
are positive constants of proportionality. A little rearrangement yields:
 must be positive, otherwise, the profit would always be negative and there would be no sense in ever having any sort of circle. Knowing that means the general shape of the profit curve as a function of r must look like:
must be positive, otherwise, the profit would always be negative and there would be no sense in ever having any sort of circle. Knowing that means the general shape of the profit curve as a function of r must look like:
 , or
, or  , or
, or  , or
, or  , or something like that. Perhaps, if we’re a bit more deeply immersed in algebra, or trigonometry, or calculus, our default vision of “answer” might be more like
, or something like that. Perhaps, if we’re a bit more deeply immersed in algebra, or trigonometry, or calculus, our default vision of “answer” might be more like  or
or  or
or  or some such expression. Note that this default vision of an “answer” is some form of mathematical object and tied to that, perhaps so intimately that we don’t see it, is the idea that this answer is easily checked. It’s the result of “doing the math correctly,” and hence, of course, we should only get one such answer. But, when we talk about the answer to a modeling problem, these are not the types of objects we’re talking about. In one very important sense, the answer to a modeling problem is a model. And, here is the first place where this idea of “no unique answer” comes into play. Because models of a given real-world situation can be constructed using wildly different mathematical tools and are based on assumptions made by the modeler, it is often the case, likely even, that two modelers approaching the same problem produce different models, i.e., different “answers” to the same modeling problem. This is the point that the first of the two statements from the APME volume above is really making.
or some such expression. Note that this default vision of an “answer” is some form of mathematical object and tied to that, perhaps so intimately that we don’t see it, is the idea that this answer is easily checked. It’s the result of “doing the math correctly,” and hence, of course, we should only get one such answer. But, when we talk about the answer to a modeling problem, these are not the types of objects we’re talking about. In one very important sense, the answer to a modeling problem is a model. And, here is the first place where this idea of “no unique answer” comes into play. Because models of a given real-world situation can be constructed using wildly different mathematical tools and are based on assumptions made by the modeler, it is often the case, likely even, that two modelers approaching the same problem produce different models, i.e., different “answers” to the same modeling problem. This is the point that the first of the two statements from the APME volume above is really making.