In his interesting recent book, Average is Over, economist Tyler Cowan spends considerable time discussing and analyzing the phenomena of “freestyle chess.” While Cowan is interested in the future of the economy, the future of work, and the impact of technology on the workplace, aspects of the freestyle chess movement struck me as a good analog for how mathematical modeling activities should play out in the classroom or in the workplace. So, today, I’d like to explore that notion a bit and introduce the idea of “freestyle math.”
Chess, of course, developed as a competitive game between two players. The relative simplicity of the rules and the absence of chance as an aspect of the game combined with the deep complexity and tremendous variety of possible play has made chess an enduring pastime played by millions for about 1400 years. For most of that time, the standard of play was human vs. human, with exceptionally talented humans becoming “grandmasters,” people who could play at extraordinarily high levels.
In the 1950’s, things began to change. Alan Turing, who we discussed in a previous post on pattern formation, realized that a computer could in principle be programmed to play chess. Turing even developed strategies for such a program and wrote chess-playing code long before the computer hardware side of the world was developed enough to execute such code. However, before long, the hardware side of the world was up to speed and by the 1970’s one could purchase a dedicated chess-playing computer that looked like this:

I recall an uncle of mine owning one of these early machines and I recall being amazed that the computer could pretty handily beat everyone I knew. But, at that time, at least, really good humans were still far better than the best chess playing machines. This too changed rapidly and in 1997, a computer called Deep Blue, developed by IBM, beat the reigning world chess champion, Gary Kasparov, 3 1/2 to 2 1/2 in a six game match. (Note that 1/2 points are awarded to each side in a draw.)
In the last eighteen years, computers have only gotten better at chess and humans, well, haven’t. Today’s most talented players don’t stand a chance against a good chess program and a good chess program can now be a single app on the phone in your pocket. However, shortly after losing to Deep Blue, Kasparov asked an interesting question – What would happen if instead of human vs. human or man vs. machine the competition were man + machine vs. man + machine. The new competitive sport of “freestyle chess” was born soon thereafter.
In this incarnation, chess is a team sport, where members of the team may be computer programs. In fact, in freestyle chess pretty much anything goes with Kasparov having remarked “Even if they were assisted by the devil, that would probably be covered by the rules.” And, in freestyle chess, something remarkable happened. Human-machine teams could defeat a single top-ranked chess playing computer program. The level of chess played by these man/machine hybrid teams was now higher than that played by either man or machine alone in the past.
Cowan describes freestyle chess matches as a being like a beehive of frenetic activity with human teams scurrying from computer to computer, combining, and analyzing suggested moves from multiple analyses before making a final decision. He also notes, interestingly, that the best freestyle teams are not necessarily made up of top chess players working with top chess computer programs. Rather, a strong freestyle team needs humans with a very different skill set. Yes, they have to understand chess and the basic elements of play, but they also need to understand computer programs, how they work, what their limitations are, what their strengths are, and how to combine the brute-force “number crunching” approach of computers effectively with human intuition.
As I read Cowan’s description of freestyle chess, I was struck by how similar the activity he described is to the activity of an effective student team working on a mathematical modeling investigation. So, I’d like to encourage you to think of mathematical modeling in your classroom as “freestyle math” and I’d like to explore for a moment some of the characteristics of what that might look like. I’m encouraging you to think of “freestyle math” in this “anything goes” sort of mindset. That is, students should be free to tap into the internet, simulation, textbooks, friends, etc., without bound. The focus should be on the goal of understanding the phenomenon they are investigating and in how one gets there, anything should be fair game. So, here are five characteristics of freestyle chess that I believe map in a one-to-one fashion to freestyle mathematical modeling:
The humans know something, but might not be super-experts
In freestyle chess, the human members of the team are not necessarily grandmaster level chess players or even master level chess players. But, at the same time, they know the rules of the game, have an understanding of strategy, and generally play as well as a decent club player (someone who plays regularly). On a modeling group in the high school classroom you want your “players” to have a roughly similar level of expertise in mathematics and have some expertise in the application area they are investigating. You don’t need a team full of math-whizzes, but you do need your students to take ownership of the mathematics, have a comfort with using mathematics, and be able to know what they need to learn.
Collaboration is key
As in freestyle chess, in freestyle math, the ability to collaborate effectively, both with other humans and with computers is a key skill. The ability to work with a diverse team is important and students also need to know how and when to use technology in their investigations. This means our students need to know when to “Google” and when to think. They need to know when to analyze with pencil and paper and when to turn to the computer.
The humans understand the strengths and limitations of computers
An essential skill of freestyle chess players is knowing both the strengths of various computer programs and the limitations of various computer programs. This is at least as important of a skill for mathematical modelers to possess. They should know to turn to the computer to fit a curve to a data set consisting of even a mildly large number of data points. At the same time, they should know what the computer is doing when it is fitting that curve, what assumptions they are making when they take that curve as being predictive, and exactly where the limitations are in what the computer is telling them. I can’t emphasize this one enough – to use a tool effectively you have to know both what it is good for and what it isn’t.
The humans are able to tap into and filter vast quantities of information
In freestyle chess, humans also bring the ability to both gather vast quantities of information and to filter this information. Freestyle math needs the same skill. Even a discerning Google search about a real-world scenario that students might investigate will return hundreds of thousands of links. Students need to be able to quickly and efficiently zoom in on the relevant information and know what information to trust and what to ignore. At the same time, a simple computer simulation can also quickly return reams of data. Students need to know how to organize this information, how to visualize this information, and again pick out what is relevant and what isn’t.
The humans supply creativity and intuition
Humans clearly bring both creativity and intuition to the table and both of these skills are required in abundance in freestyle chess and in freestyle math. In mathematical modeling, decisions, false starts, retrenchments, intuition, and creativity are the norm. Students need to be able to offload to a computer the things it does best and bring to the table the sorts of creative approaches and intuition that they do best.
As you work to engage your students in the practice of mathematical modeling I’d encourage you to think “freestyle math” and look to freestyle chess as a model for what open collaboration between people and between man and machine can produce. I’d also encourage you to think about the skills that such activities demand that go beyond the simple mastery of mathematical procedures, and how freestyle math demands a deep understanding of concepts and the ability to integrate that knowledge in the pursuit of understanding the world.
John

 . If we think of this in terms of applications, we often pose direct problems as well. Here, for example, we might say, suppose we drop a ball from a height
. If we think of this in terms of applications, we often pose direct problems as well. Here, for example, we might say, suppose we drop a ball from a height  , we assume air resistance is negligible, how fast is the ball traveling when the ball hits the ground? Or perhaps, how long will it take the ball to hit the ground?
, we assume air resistance is negligible, how fast is the ball traveling when the ball hits the ground? Or perhaps, how long will it take the ball to hit the ground? . Further, we can suppose that
. Further, we can suppose that  , and the time it takes the sound to travel back up the well,
, and the time it takes the sound to travel back up the well,  . Our measured time is then the sum of these two:
. Our measured time is then the sum of these two:

 is the gravitational acceleration and
is the gravitational acceleration and  is the speed of sound in air. A quick plot of
is the speed of sound in air. A quick plot of 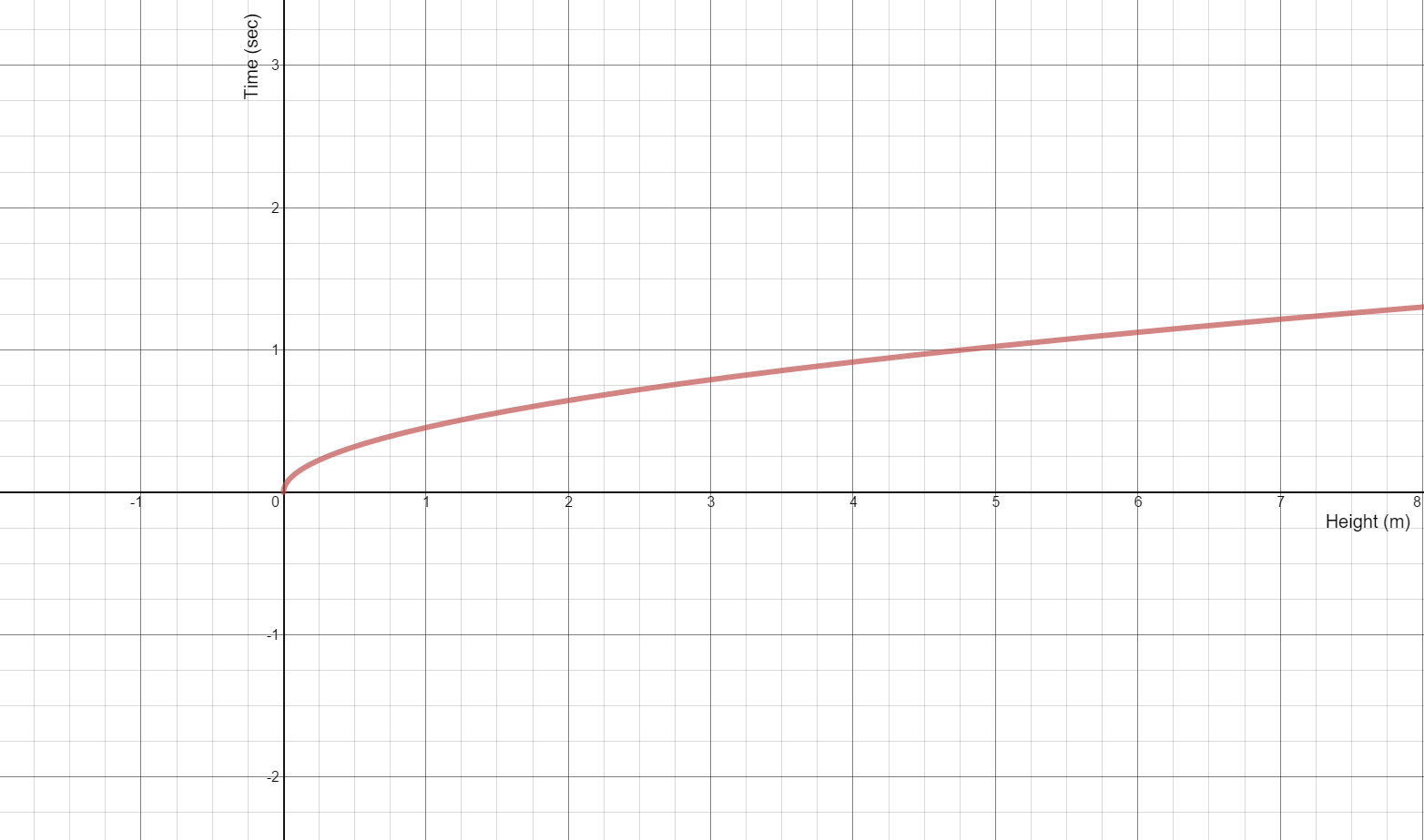
 term is important here or when it may be important. It’s also worth taking time exploring how an error in the measurement of
term is important here or when it may be important. It’s also worth taking time exploring how an error in the measurement of 
 is the amount of stuff at time
is the amount of stuff at time  , you’d write:
, you’d write:


 , is equal to the amount of stuff we have now,
, is equal to the amount of stuff we have now,  . That is, in a little bit, the world looks just like it does now, with a tiny change. We do this repeatedly, and we get a picture of how our system changes according to the underlying process of changing by constant small steps.
. That is, in a little bit, the world looks just like it does now, with a tiny change. We do this repeatedly, and we get a picture of how our system changes according to the underlying process of changing by constant small steps.